Yes, in fact I did !
While this post does not involve any comfort food, it involves a quarter million E-Mails, go and me wondering about the flow of SSH bruteforce attempts against my server.
Introduction Link to heading
If you are administering your own linux-based cloud infrastructure, you likely have some kind of managment interface to your instance. While this can take all sorts of forms, it’s not uncommon to just have a SSH server listening to the public Internet. One of the desgin goals of SSH was precisely this, so there is nothing wrong with this choice in and of itself.
However, should you choose to do so, it is absolutely imperative that you secure the SSH access, either with a very strong password or a private key. The correct configuration is up to you and outside the scope of this post.
With all of this in place, you will still see a lot of traffic hitting your server. Almost all of it will originate from automated crawlers looking for a weak password to hijack your server and abuse it to relay malicious traffic, install cryptocurrency miners, make your server part of a botnet or other non-fun things.
As soon as your IP is reachable, you can check with tail -F /var/log/auth.log and observe the live auth attempts coming in.

There are “best practice” guides that suggest to move the SSH Port from 22 to some higher port like 2222, 22022 or some other more-or-less random high port. Personally, I don’t really care.
While it will reduce the flood of connection attempts somewhat, a proper portscan will still find the listening port so it’s simply a matter of slightly reducing the load on your server.
One thing I like to do though, is to install Fail2Ban.
Fail2Ban Link to heading
As you can see from the github repo, Fail2Ban is a simple but very effective tool to (temporarily) block IP addresses from connecting to your server once they exceed a certain threshold of SSH authentication attempts. While the configuration of Fail2Ban is outside the scope of this post, I highly recommend you check it out and configure it on your server(s).
One cool feature Fail2Ban has, is that it supports sending E-Mails. Obviously this requires that your server is able to send E-Mails in the first place. While there a million different ways to make this work, I have opted to just use sendmail to send the E-Mails via gmail. As with other pre-requisites, this is left as an excercise for the reader 🙂
So, everytime an IP gets banned from my server, I will receive an E-Mail with the whois lookup for the offending IP address.
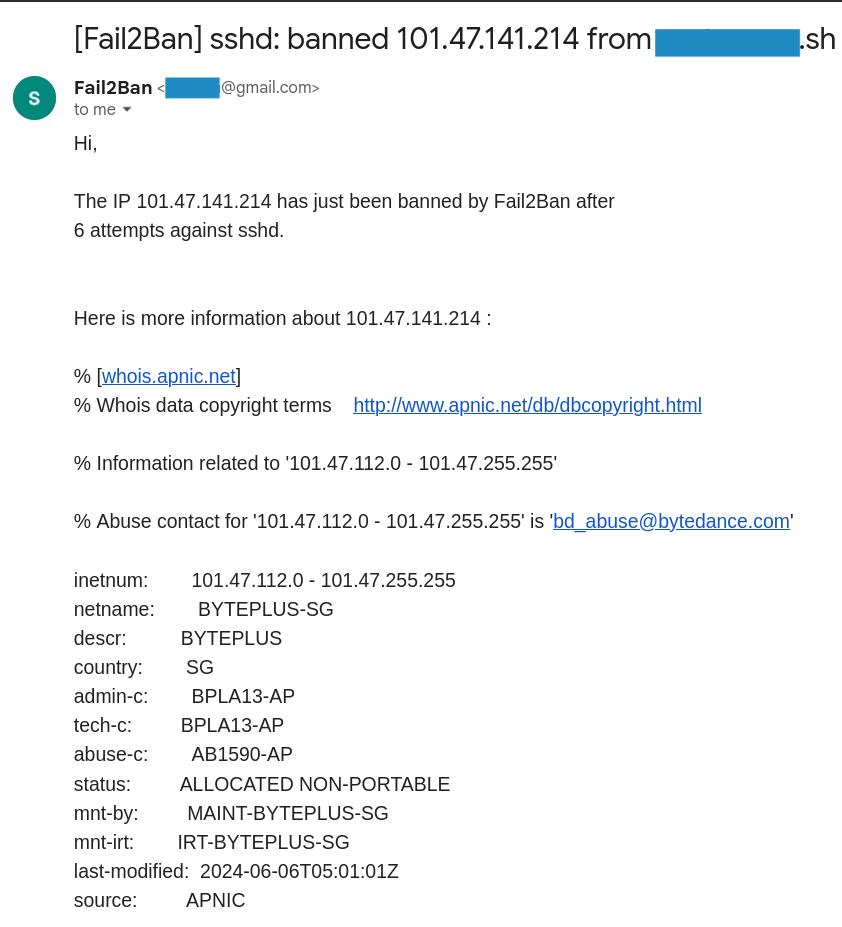
Even though there is plenty of space with a free gmail account (15GB), you will get a lot of E-Mails. I have had this setup running for a few months on one of my servers and ended up with around 265k E-Mails. I have some rules configured so they all get tagged with a monitoring tag, that way it’s easy to keep track of them.
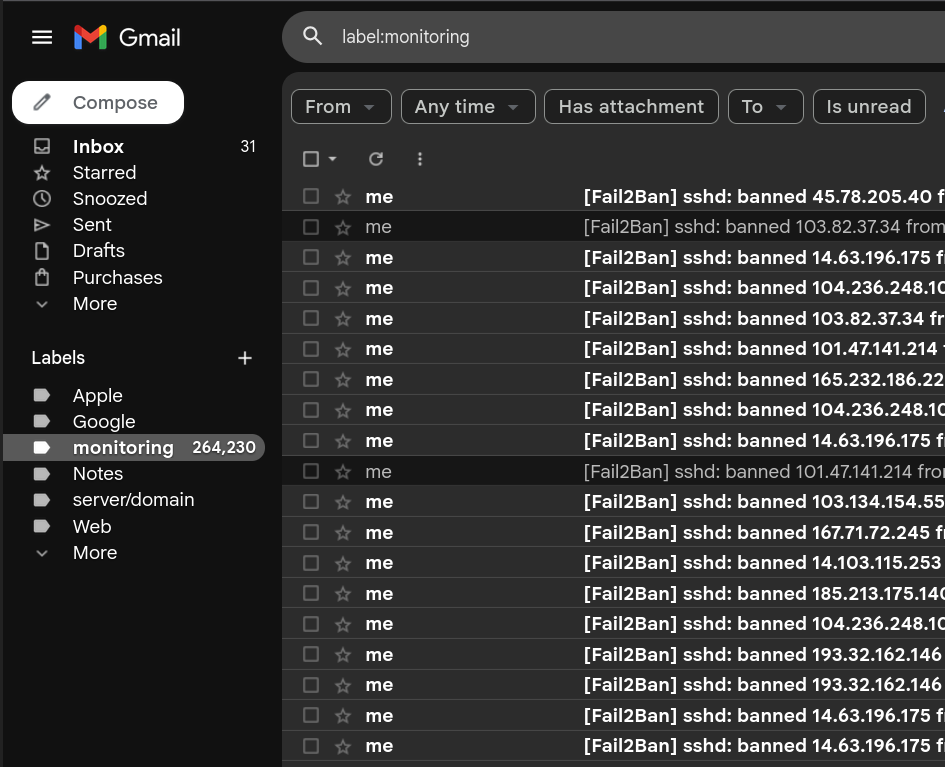
With this kind of dataset, I wanted to compute some simple stats and do some simple visualization, so let’s explore how to parse this.
Exporting the raw data Link to heading
The first order of business is obvious, we need to obtain this data in some form that is machine-readable so we can actually build some code that feeds on this. Referring to the title of this post, there exists a (not widely known) google service that lets you do this, called Google Takeout.
The service itself is quite simple, once you are logged in, you are given a list of google services that store data about you.
In our case we are only interested in the gmail service so we select that.
Because we had the foresight to tag the E-Mails, we can nicely filter for this tag. Although in my case there really isn’t much else in this gmail account, its still a handy way to reduce the export size.
After we submitted our request, we have to wait a little bit for google to pull the data. In my case (gmail export with only specially tagged mails) I had to wait around 15 hours until I got the notification that my export was ready to be downloaded.
In the end, I got an E-Mail with a download link to a 126MB .zip file.
1dave:hackbook > ~/Downloads $ ll |grep take
2.rw-r--r-- dave staff 126 MB Mon Dec 22 14:09:38 2025 -- takeout-20251221T232223Z-3-001.zip
After we unzip, we can see we have a human-readable export of our mails, inflated in size to 1GB.
1dave:hackbook > ~/Downloads $ file Takeout/Mail/monitoring.mbox
2Takeout/Mail/monitoring.mbox: Unicode text, UTF-8 text, with CRLF line terminators
3dave:hackbook > ~/Downloads $ ll Takeout/Mail/monitoring.mbox
4.rw-r--r-- dave staff 1.0 GB Mon Dec 22 04:50:42 2025 -- Takeout/Mail/monitoring.mbox
We do some simple regex matching to get a rough idea how many entries we have.
If you recall the screenshot of our inbox, it seems we have more records in the export than are shown in the inbox (290k vs 265k). For now this will not bother us too much, it could be due to multiple factors like the regex not matching or the tagging being imprecise.
As we will have to parse the dataset anyway, we will just see what we end up with in the end. From a ballpark perspective it looks correct atleast.
To get a feel for the data we are parsing, its always a good idea to have a peek. For readability reason, I have redacted the whois output and annotated the record.
1From 1852025394426747236@xxx Sat Dec 20 11:10:51 +0000 2025 // start of record
2X-GM-THRID: 1852025394426747236
3X-Gmail-Labels: Archived,Sent,Unread,monitoring
4Return-Path: <USER@gmail.com>
5Received: from DOMAIN.sh ([185.165.169.87])
6 by smtp.gmail.com with ESMTPSA id a640c23a62f3a-b8037f0ecb9sm465552566b.56.2025.12.20.03.10.52
7 for <USER@gmail.com>
8 (version=TLS1_3 cipher=TLS_AES_256_GCM_SHA384 bits=256/256);
9 Sat, 20 Dec 2025 03:10:52 -0800 (PST)
10From: Fail2Ban <USER@gmail.com>
11X-Google-Original-From: Fail2Ban <fail2ban@DOMAIN.sh>
12Received: from DOMAIN.sh (DOMAIN.sh [127.0.0.1])
13 by DOMAIN.sh (8.15.2/8.15.2/Debian-22ubuntu3) with ESMTP id 5BKBAps02305687
14 for <USER@gmail.com>; Sat, 20 Dec 2025 12:10:51 +0100
15Received: (from root@localhost)
16 by DOMAIN.sh (8.15.2/8.15.2/Submit) id 5BKBApbq2305683
17 for USER@gmail.com; Sat, 20 Dec 2025 12:10:51 +0100
18Message-Id: <202512201110.5BKBApbq2305683@DOMAIN.sh>
19Subject: [Fail2Ban] sshd: banned 217.154.62.22 from DOMAIN.sh
20Date: Sat, 20 Dec 2025 12:10:51 +0100
21To: USER@gmail.com
22
23Hi,
24
25The IP 217.154.62.22 has just been banned by Fail2Ban after
265 attempts against sshd.
27
28Here is more information about 217.154.62.22 :
29
30// imagine output of whois(ip) here
31// not shown for readability
32
33Regards,
34
35Fail2Ban
36
37From 1851658481004358137@xxx Tue Dec 16 09:58:56 +0000 2025 // next record starts here
As you can see, its basically just cleartext E-Mails all concatinated together. In case you are wondering, this format is called Mbox and while there is an RFC for it, it specifically states that It does not specify an Internet standard of any kind..
Now that we understand the structure (or lack thereof …) we are working with, lets explore some strategies on how we could parse this.
WHOIS vs. RDAP vs. API Link to heading
Looking at this data, its not a stretch to come up with a few questions, such as
- What country or network is the worst offender, i.e. originates the most bruteforce attempts ?
- Which IP is the most common ?
- Connections over Time ?
I wanted answers to these questions. I decided to throw some go code together.
Conceptually, its quite simple. Just loop over the file, parse each message, compute some simple stats and draw some pretty graphs.
What I hadn’t prepared for, was the mess that is freetext protocols.
As you might recall, in the body of our E-Mails is the whois result of a banned IP.
In case you aren’t aware, WHOIS is one of those ancient protocols. It origniated in the 70s but has a relatively modern RFC.
When we do a whois lookup on our local linux machine, we see the same output as in the E-Mail.
1dave:devcube > ~ $ whois 88.205.172.170
2% This is the RIPE Database query service.
3% The objects are in RPSL format.
4%
5% The RIPE Database is subject to Terms and Conditions.
6% See https://docs.db.ripe.net/terms-conditions.html
7
8% Note: this output has been filtered.
9% To receive output for a database update, use the "-B" flag.
10
11% Information related to '88.205.160.0 - 88.205.191.255'
12
13% Abuse contact for '88.205.160.0 - 88.205.191.255' is 'abuse@rt.ru'
14
15inetnum: 88.205.160.0 - 88.205.191.255
16netname: USI_ADSL_USERS
17descr: Dynamic distribution IP's for broadband services
18descr: OJSC RosteleÓom, regional branch "Urals"
19country: RU
20admin-c: UPAS1-RIPE
21tech-c: UPAS1-RIPE
22status: ASSIGNED PA
23mnt-by: ROSTELECOM-MNT
24created: 2006-12-18T06:59:53Z
25last-modified: 2025-12-17T11:15:36Z
26source: RIPE
27
28role: Uralsvyazinform Perm Administration Staff
29address: 11, Moskovskaya str.
30address: Yekaterinburg, 620014
31address: Russian Federation
32admin-c: SK2534-RIPE
33admin-c: DK2192-RIPE
34admin-c: SK3575-RIPE
35admin-c: TA2344-RIPE
36tech-c: DK2192-RIPE
37tech-c: SK3575-RIPE
38tech-c: TA2344-RIPE
39nic-hdl: UPAS1-RIPE
40mnt-by: MFIST-MNT
41created: 2007-09-18T08:50:24Z
42last-modified: 2019-02-14T06:36:03Z
43source: RIPE # Filtered
44
45% Information related to '88.205.128.0/17AS12389'
46
47route: 88.205.128.0/17
48descr: Rostelecom networks
49origin: AS12389
50mnt-by: ROSTELECOM-MNT
51created: 2018-10-31T08:19:54Z
52last-modified: 2018-10-31T08:19:54Z
53source: RIPE # Filtered
54
55% This query was served by the RIPE Database Query Service version 1.120 (DEXTER)
While this looks definitely parsable and machine-friendly, there are some details here that we need to consider. This data obviously does not come from my local machine but it was queried from the WHOIS server that holds that information for this IP.
I won’t go into too much detail here, but essentially the “Big 5” of the Internet each provide WHOIS servers for their allocated IP ranges.
The local whois client just queries these servers. That’s not a problem as long as they all stick to the same format, right ? Riiiight ?
Yeah, no.
WHOIS Link to heading
It turns out, whois lookups can vary by quite some degree.
Take these two lookups for example, whois 88.205.172.170 and whois 157.245.116.190.
1dave:devcube > ~ $ whois 88.205.172.170
2% This is the RIPE Database query service.
3% The objects are in RPSL format.
4%
5% The RIPE Database is subject to Terms and Conditions.
6% See https://docs.db.ripe.net/terms-conditions.html
7
8% Note: this output has been filtered.
9% To receive output for a database update, use the "-B" flag.
10
11% Information related to '88.205.160.0 - 88.205.191.255'
12
13% Abuse contact for '88.205.160.0 - 88.205.191.255' is 'abuse@rt.ru'
14
15inetnum: 88.205.160.0 - 88.205.191.255
16netname: USI_ADSL_USERS
17descr: Dynamic distribution IP's for broadband services
18descr: OJSC RosteleÓom, regional branch "Urals"
19country: RU
20admin-c: UPAS1-RIPE
21tech-c: UPAS1-RIPE
22status: ASSIGNED PA
23mnt-by: ROSTELECOM-MNT
24created: 2006-12-18T06:59:53Z
25last-modified: 2025-12-17T11:15:36Z
26source: RIPE
27
28role: Uralsvyazinform Perm Administration Staff
29address: 11, Moskovskaya str.
30address: Yekaterinburg, 620014
31address: Russian Federation
32admin-c: SK2534-RIPE
33admin-c: DK2192-RIPE
34admin-c: SK3575-RIPE
35admin-c: TA2344-RIPE
36tech-c: DK2192-RIPE
37tech-c: SK3575-RIPE
38tech-c: TA2344-RIPE
39nic-hdl: UPAS1-RIPE
40mnt-by: MFIST-MNT
41created: 2007-09-18T08:50:24Z
42last-modified: 2019-02-14T06:36:03Z
43source: RIPE # Filtered
44
45% Information related to '88.205.128.0/17AS12389'
46
47route: 88.205.128.0/17
48descr: Rostelecom networks
49origin: AS12389
50mnt-by: ROSTELECOM-MNT
51created: 2018-10-31T08:19:54Z
52last-modified: 2018-10-31T08:19:54Z
53source: RIPE # Filtered
54
55% This query was served by the RIPE Database Query Service version 1.120 (SHETLAND)
1dave:devcube > ~ $ whois 157.245.116.190
2#
3# ARIN WHOIS data and services are subject to the Terms of Use
4# available at: https://www.arin.net/resources/registry/whois/tou/
5#
6# If you see inaccuracies in the results, please report at
7# https://www.arin.net/resources/registry/whois/inaccuracy_reporting/
8#
9# Copyright 1997-2025, American Registry for Internet Numbers, Ltd.
10#
11
12
13NetRange: 157.245.0.0 - 157.245.255.255
14CIDR: 157.245.0.0/16
15NetName: DIGITALOCEAN-157-245-0-0
16NetHandle: NET-157-245-0-0-1
17Parent: NET157 (NET-157-0-0-0-0)
18NetType: Direct Allocation
19OriginAS:
20Organization: DigitalOcean, LLC (DO-13)
21RegDate: 2019-05-09
22Updated: 2020-04-03
23Comment: Routing and Peering Policy can be found at https://www.as14061.net
24Comment:
25Comment: Please submit abuse reports at https://www.digitalocean.com/company/contact/#abuse
26Ref: https://rdap.arin.net/registry/ip/157.245.0.0
27
28
29
30OrgName: DigitalOcean, LLC
31OrgId: DO-13
32Address: 105 Edgeview Drive, Suite 425
33City: Broomfield
34StateProv: CO
35PostalCode: 80021
36Country: US
37RegDate: 2012-05-14
38Updated: 2025-04-11
39Ref: https://rdap.arin.net/registry/entity/DO-13
40
41
42OrgAbuseHandle: DIGIT19-ARIN
43OrgAbuseName: DigitalOcean Abuse
44OrgAbusePhone: +1-646-827-4366
45OrgAbuseEmail: abuse@digitalocean.com
46OrgAbuseRef: https://rdap.arin.net/registry/entity/DIGIT19-ARIN
47
48OrgTechHandle: NOC32014-ARIN
49OrgTechName: Network Operations Center
50OrgTechPhone: +1-646-827-4366
51OrgTechEmail: noc@digitalocean.com
52OrgTechRef: https://rdap.arin.net/registry/entity/NOC32014-ARIN
53
54OrgNOCHandle: NOC32014-ARIN
55OrgNOCName: Network Operations Center
56OrgNOCPhone: +1-646-827-4366
57OrgNOCEmail: noc@digitalocean.com
58OrgNOCRef: https://rdap.arin.net/registry/entity/NOC32014-ARIN
59
60
61#
62# ARIN WHOIS data and services are subject to the Terms of Use
63# available at: https://www.arin.net/resources/registry/whois/tou/
64#
65# If you see inaccuracies in the results, please report at
66# https://www.arin.net/resources/registry/whois/inaccuracy_reporting/
67#
68# Copyright 1997-2025, American Registry for Internet Numbers, Ltd.
69#
If you look carefully, you’ll see that one lookup is provided by RIPE and the other one by ARIN.
The structure is also very much not the same, fields are either missing or called by other names, like OrgName vs desc or NetRange vs. inetnum.
Parsing this correctly while accounting for changes in the format like …
- missing fields
- incorrectly labeled entries
- made up crap by the people responsible for registering their operator info
… was certainly a rabbit hole I whished I had avoided. Anyway, let this serve as a cautionary tale.
I eventually found myself giving up on the idea of ever parsing the existing whois records with a high-enough accuracy.
RDAP Link to heading
As it turns out, other people also encountered this very same problem and instead of complaining about it, actually came up with a better alternative, which is called RDAP. This protocal addresses a lot of the headaches of WHOIS. If you really want to dig deep, there is a proper RFC for it.
Essentially, it’s a more REST-y way to do this, enforcing a strict standard that makes it much easier to programatically access this data. As with WHOIS, RDAP servers are provided by the 5 Regional Internet Registries.
I won’t paste the full RDAP results for 157.245.116.190 and 88.205.172.170 here as they are both pretty long, but you can checkout their gists here and here.
In case you want to play with it without installing a local RDAP client, there is a handy online client available.
Ok, so it seems we have settled on RDAP then ?
Not quite.
API Link to heading
When I began implementing the RDAP logic I did “raw” HTTP calls at first, then later switched to OpenRDAP. While functionally it worked perfectly, the lookups were too slow for the scale I needed.
When doing simple, non-concurrent and blocking lookups (aka the worst possible way to do this), the first couple hundred lookups were done in an okay-ish time before getting stalled by the server.
Improving on this, I used non-blocking and concurrent lookups, which pushed this to the scale of a couple of thousand lookups before we encountered the server bottleneck. The problem was that I didn’t need to do a couple dozens, hundreds or thousands of lookups.
I needed tens to hundreds of thousand lookups. I needed a proper API that scales.
As I’m sure you are aware, there are many different versions of the same “what is my ip ?” website floating around, like here, here or here.
Old habits die hard, as they say, and a couple of years ago I discovered IPinfo.io and it stuck, mainly because you can super easily curl for a quick check.
1dave:devcube > ~ $ curl ipinfo.io/1.1.1.1
2{
3 "ip": "1.1.1.1",
4 "hostname": "one.one.one.one",
5 "city": "Hong Kong",
6 "region": "Hong Kong",
7 "country": "HK",
8 "loc": "22.2783,114.1747",
9 "org": "AS13335 Cloudflare, Inc.",
10 "postal": "999077",
11 "timezone": "Asia/Hong_Kong",
12 "readme": "https://ipinfo.io/missingauth",
13 "anycast": true
14}
I decided to use this service as they even provide their own go client so byebye manually HTTP request’ing. Once you register an account there, you will get access to a Free-Tier Lite-API token.
With the code in place and our workerpool at the ready, now all that is left to do is to run it against our export.
Results Link to heading
You can pull the code from the repo and run it against your own sample, this was done against the export mentioned above.
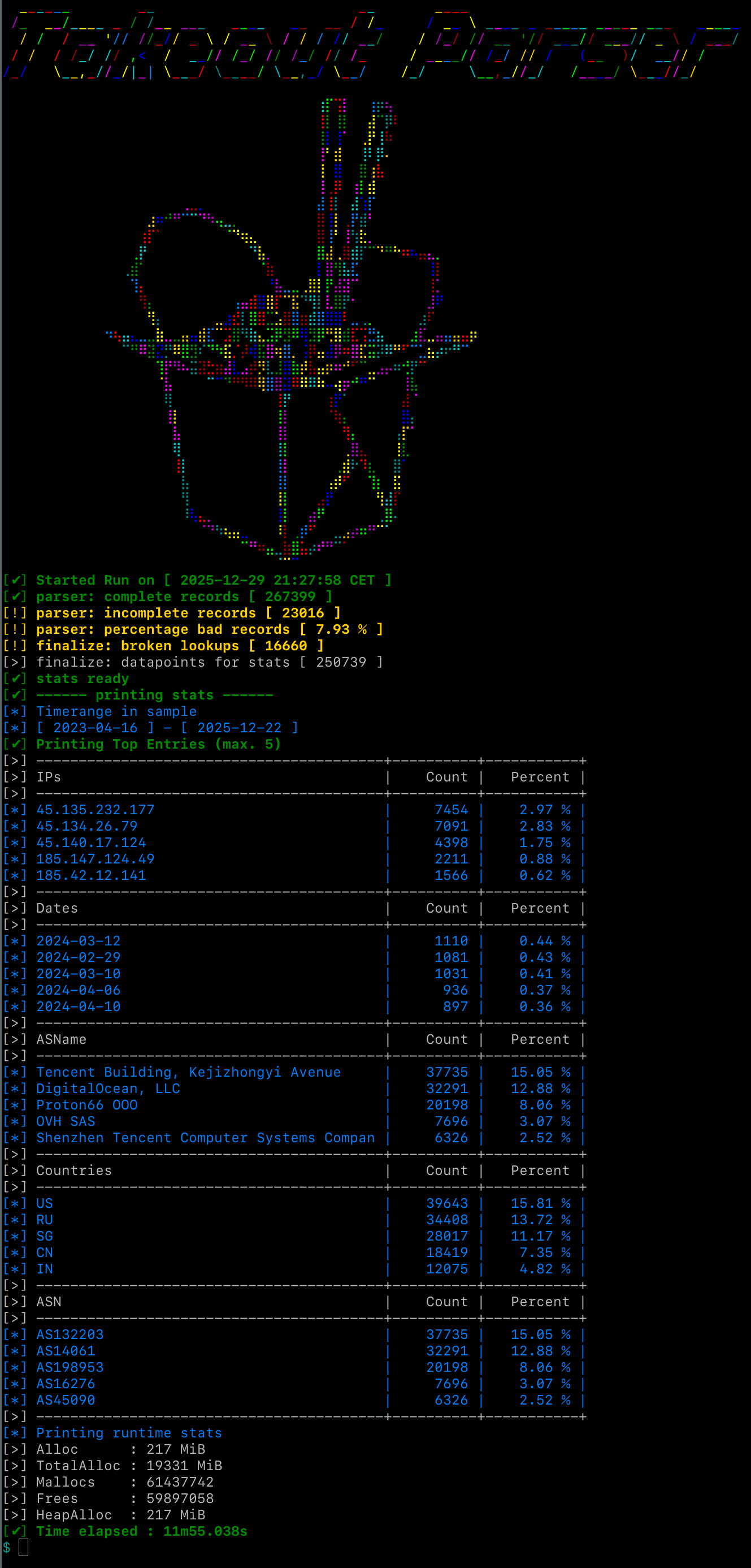
When we look at the output log, we see some numbers that warrant special consideration.
Namely that from our initial input set, we discard 7.93% or roughly 23k records. This can be due to a multitude of factors related to our input data, such as
-
An E-Mail record is “broken” in the sense that it is missing information like the IP address.
-
The record being malformatted (for example by things like Unicode encoding).
-
The local
whoislookup, done by Fail2Ban on the server, failed to return valid data.
The point is, its outside our (immediate) control unless we want to parse the format ourself or dig deeper into the internals of the package we use. Likely, for the reasons mentioned, there will always be “broken” records in this export, so we have to accept some kind of leakage.
At this time, I think we can live with <10%.
Next up is broken lookups, these look less like “outside our control”.
I must say, I don’t like it. This is something that could be investigated and improved, but maybe this is price to pay when doing this with a free-tier API and concurrent lookups sharing one client. For now we will keep this in the backlog.
Also note the Timerange in sample, didn’t I say earlier that I had this setup for a few months ? Time really does seem to fly …
To be clear about the numbers, they break down like this
1 267399 complete records
2+ 23016 incomplete records
3--------
4 290415 total records in the .mbox export
5
6
7 267399 complete records passed into ip lookup
8- 16660 failed api lookups
9--------
10 250739 stats calculation is done on this many (now fully intact) records
If you recall, 290415 was also the number we got from our initial peek of the file.
This is good because it means the error is in the records themself, not in the parser being broken in some way.
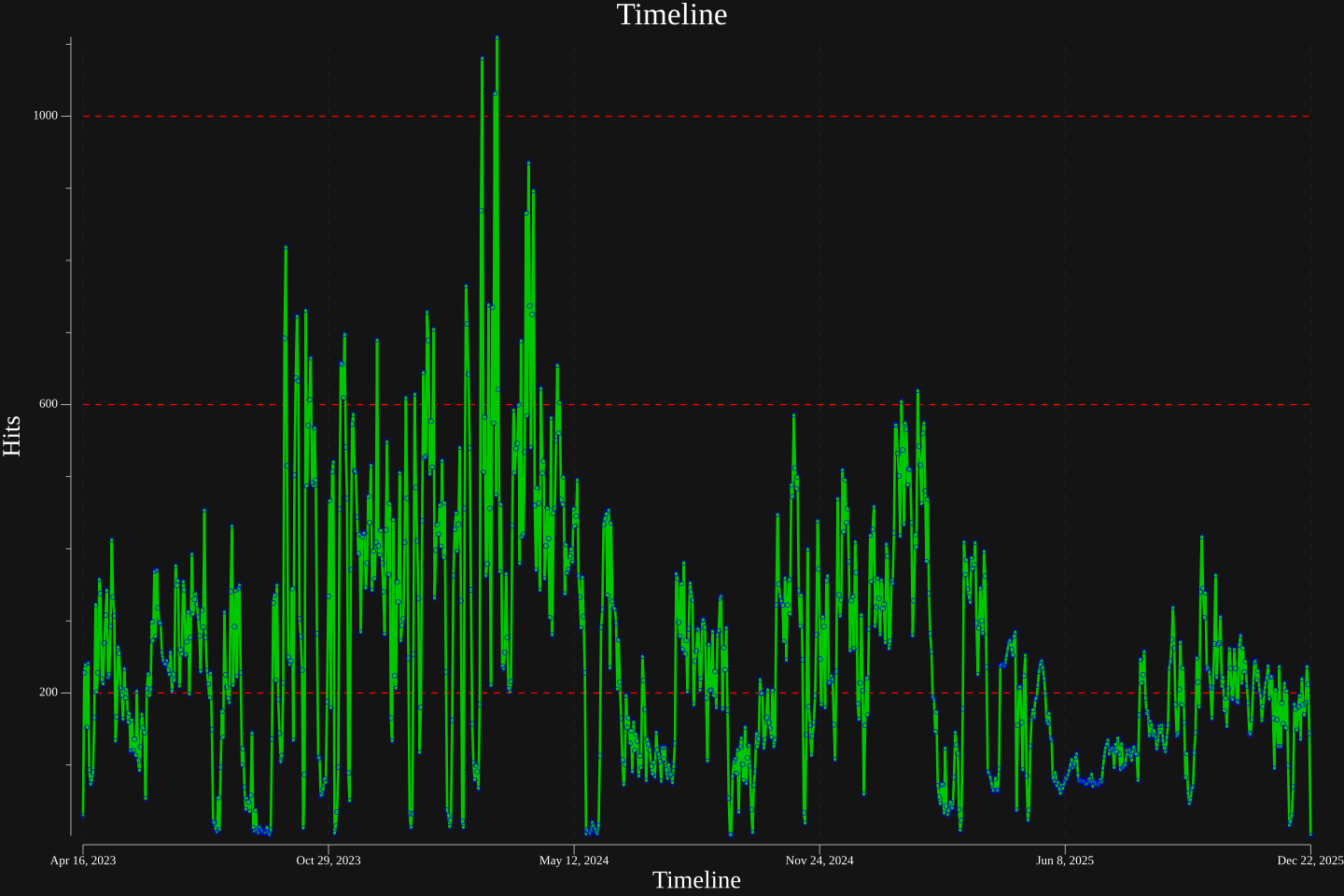
Let’s check out some of the plots.
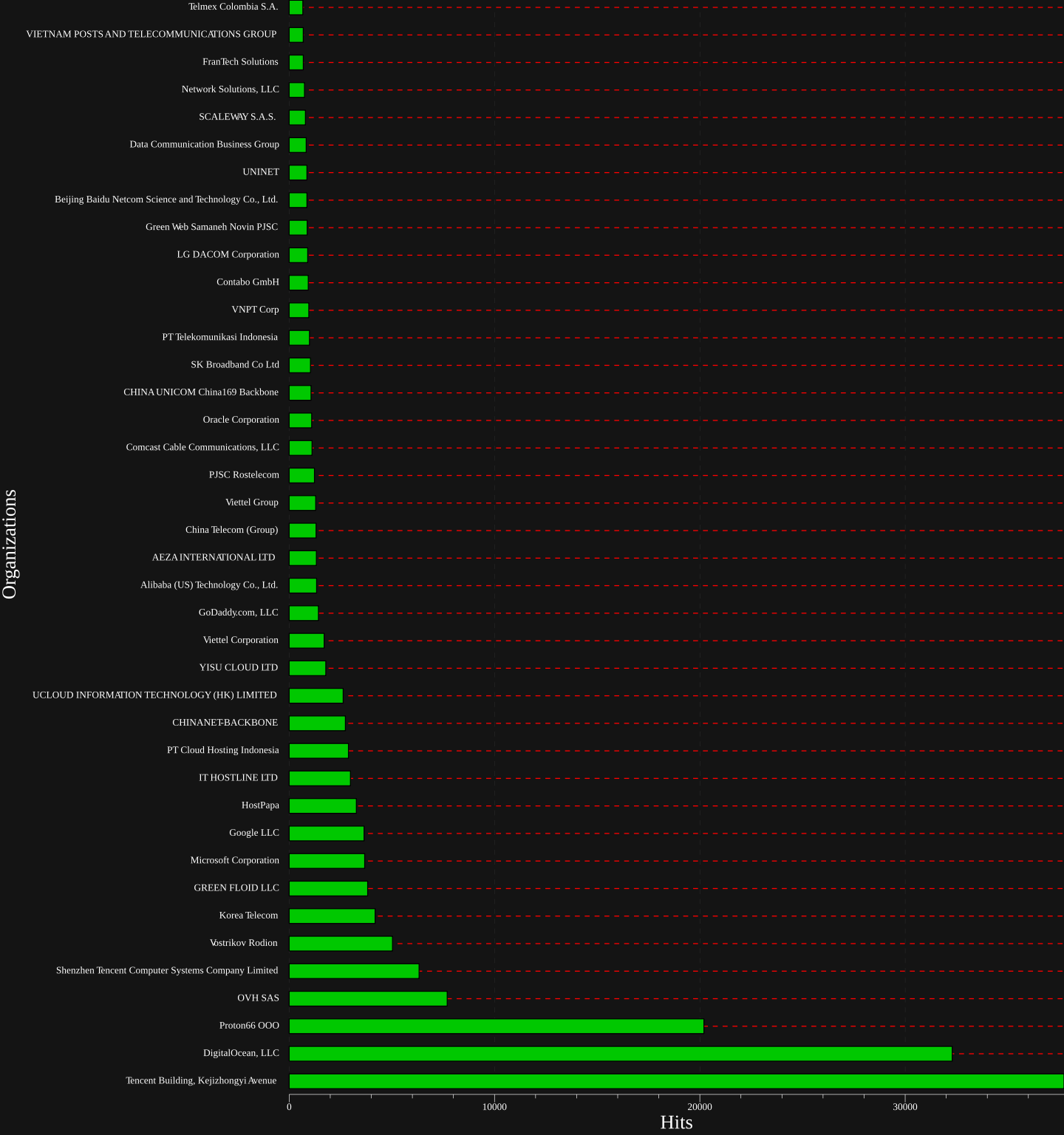
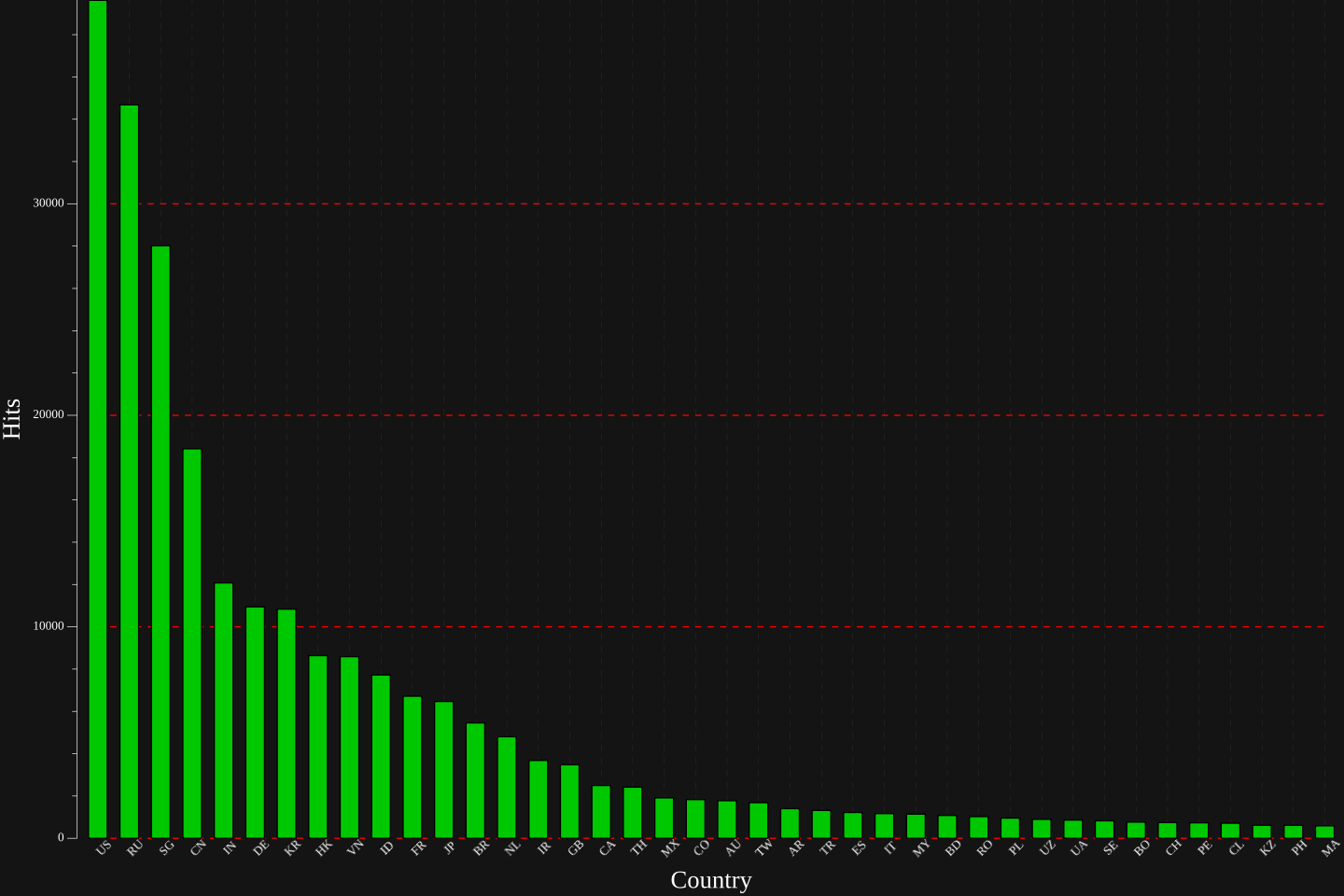
Improvements & Review Link to heading
This was a super fun project and I kind of fell in love with go and its ecosystem while doing it.
Still, there is room for improvement. Some things I thought about but did not end up doing or benched for later.
-
Do more diagnostic to find out why the Parsing & API lookup fail.
-
Use concurrency for data input (i.e. mbox parser), not just API lookups.
-
Optimize concurrency strategy, test more models beyond workerpool.
-
Perhaps go full premium on the API and display more precise stats.
-
3D coordinates plotted on an interactive World Map in the browser ? 🤔
-
Ditch E-Mail and Big-Tech services entirely and use something like a selfhosted ntfy instance.